Web Dev Part 2: Requesting A Webpage
This is part 2 in a multi-series post. If you did not read part 1, you could find it here. Now that you are familiar with:
Recap
- How elements are displayed on the page
- The way a page gets its look and feel
- How a page becomes searchable by bots
- The way a page gets its functionality to perform tasks
It’s time to talk about how data, such as user information, is populated on a website. For example, how do all those Facebook posts get displayed in your news feed? They must be coming from somewhere, right?
Finding the address
The moment you hit enter your browser’s address bar and navigate to Facebook, or click on a Facebook link, your browser will request its real address. Think of your browser calling an operator and saying, ‘I would like to call Facebook’. These operators are known as Root Servers, in which there are 13 unique ones around the world. This operator, or root server, will give your browser the address to Facebook; for example, “Facebooks address is 31.13.71.36”. Once your browser has this information, it can make the request to Facebook. Upon making this request, your browser will also attach information about who you are, via cookies, so that Facebook would know who you are and look up your info in their systems.
DISCLAIMER: Please note that below we explain how large systems work. The below examples do not reflect how Facebook operates. We are using Facebook as an example of how a website of its size would operate. We do not make any claims that the below description is Facebooks’s architecture.
Before entering Facebook’s network, your request goes through many other Networks. It’s important to know that your request does not teleport directly to its destination. Before it gets to the address that was provided to you by the operator, it has to travel through many other networks. Think of this as if you were driving from New York to California and have to pass through many states along the way. During this travel, the contents of your request, such as personal information, may or may not be projected. This is what HTTPS helps with, as opposed to HTTP. HTTPS encrypts your data so that only Facebook can read it. Think of this as locking your car door on your way to Cali, and only you and your Friend in Cali can open the car door.
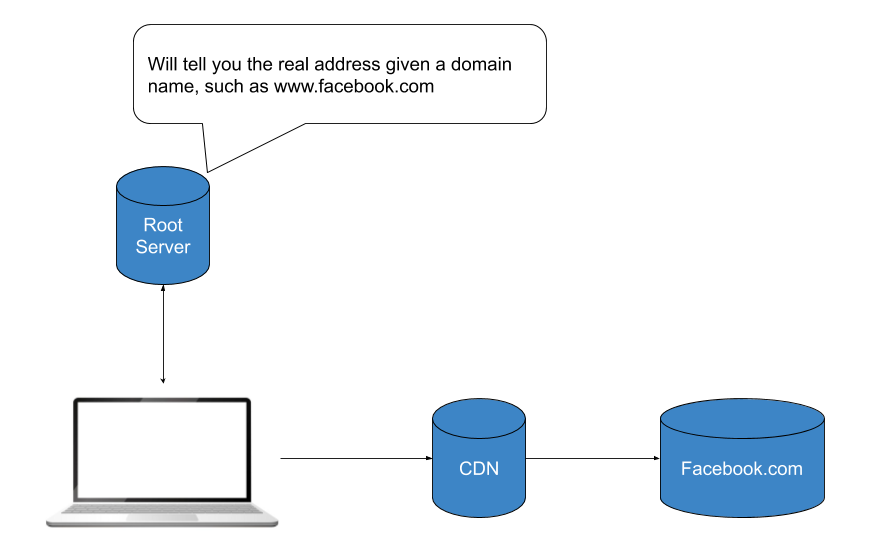
As your request approaches its final destination, it will most likely arrive at a CDN, content delivery network. This means that if others have requested similar content, it will just reply to you with that same data. The reason for a company to place themselves behind a CDN is for both security and performance. If millions of users were requesting the same page that is the same no matter who the user is, why have that request go into your company’s systems to process. Likewise, if you were getting DDOSed, Denial-of-service attack, you can have your CDN protect you with some security measures, such as IP blocking.
If the CDN does not have the content your request is asking for, it will forward your request to Facebook. After this long journey, your request finally gets to Facebook, and it’s time for them to reply!
One Reply to “Web Dev Part 2: Requesting A Webpage”
Comments are closed.